Java ThreadPoolExecutor 源码分析
发表于 2020-10-01,预计阅读时间 3 分钟
前言
本篇文章对 JDK8 线程池框架中 ThreadPoolExecutor 类进行源码分析,将会从 ThreadPoolExecutor 工作机制角度分析它在 状态管理、提交任务、执行任务、回收线程 和 拒绝任务 阶段的设计思路和代码实现。线程池框架的介绍和使用不在本篇文章涵盖的范围之内。
ThreadPoolExecutor 的工作机制可以参考我摘记的 《Java 并发编程实战》笔记 - 线程池的使用 - 配置 ThreadPoolExecutor 篇章。
状态管理
ThreadPoolExecutor 内部共有两个状态:workerCount 和 runState。workerCount 表示线程池中的有效线程数,是已经被允许运行并且还未结束的线程数量。runState 表示线程池在生命周期内的运行状态,具体的枚举值有 RUNNING、SHUTDOWN、STOP、TIDYING、TERMINATED。
ThreadPoolExecutor 将 workerCount 和 runState 两个状态合并在同一个 AtomicInteger 类型的 ctl 字段中,并会通过一系列位运算来分别获取设置 workerCount 和 runState 的具体值。其中,runState 会占据 ctl 字段中 int 值的高 3 位,workerCount 会占据剩下的 29 位,因此 ThreadPoolExecutor 支持的最大线程数量是 2^29 - 1 个,而不是 2^32 -1 个。ctl 字段中具体的位分配如下所示:
[000][0 0000 0000 0000 0000 0000 0000 0000]
| |
v v
runState workerCount
将 workerCount 和 runState 两个状态设计成同一个字段的好处是可以使用一次 CAS 操作同时修改两个状态,从而避免 竞态条件 的发生和减少锁资源的占用。
ThreadPoolExecutor 源码中定义 ctl 字段,以及通过位运算来获取 workerCount 和 runState 的代码片段如下:
workerCount
workerCount 表示线程池中的有效线程数,其初始值为 0,会占据 ctl 字段中 int 值的低位,只需使用 AtomicInteger 的 CAS 操作即可线程安全地修改其值。
ThreadPoolExecutor 源码中修改 workerCount 的代码片段如下:
runState
runState 表示线程池在生命周期内的运行状态,其初始值为 RUNNING,各个枚举值以及其对应的状态描述和状态之间的转换流程如下所示:
| 枚举值 | 数值 | 描述 |
|---|---|---|
| RUNNING | 111 | 接收新的任务,处理队列中的任务 |
| SHUTDOWN | 000 | 不再接收新的任务,但会处理队列中的任务 |
| STOP | 001 | 不再接收新的任务,不会处理队列中的任务,会中断进行中的任务 |
| TIDYING | 010 | 所有任务已经终止,workerCount 已经为零,准备调用 terminated() 钩子方法 |
| TERMINATED | 011 | 调用 terminated() 钩子方法已经完成 |
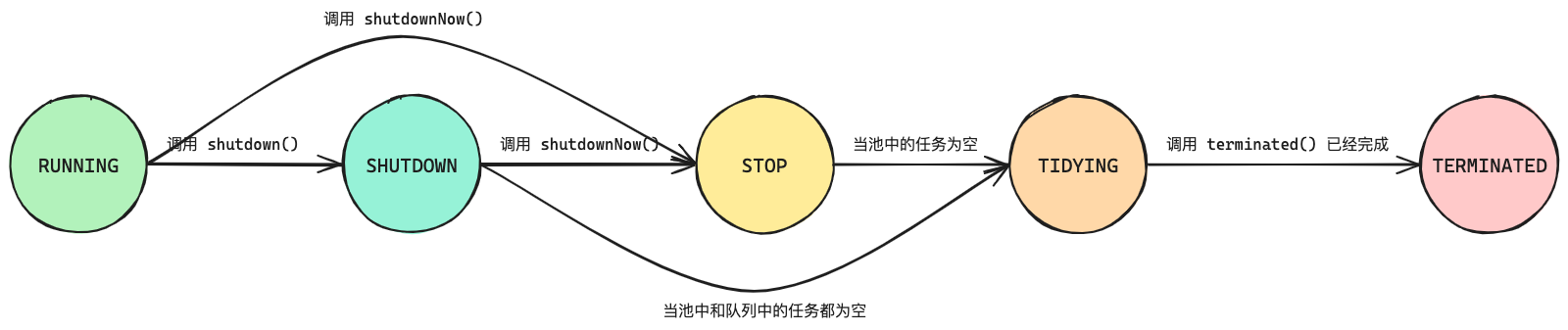
将 runState 设计成上述五个枚举值的原因在于 ThreadPoolExecutor 内部的工作机制。首先,ThreadPoolExecutor 包含了一个用于缓冲任务执行的 workQueue,所以在关闭线程池的时候也需要考虑到 workQueue 中的线程状态(是否需要中断线程)。此外,ThreadPoolExecutor 还提供了一些待实现的扩展方法:beforeExecute(Thread, Runnable)、afterExecute(Runnable, Throwable)、terminated(),因此这些方法的执行进度也需要被考虑在线程池的运行状态之内。
ThreadPoolExecutor 源码中定义 runState 枚举值,以及判断当前运行状态的代码片段如下:
提交任务
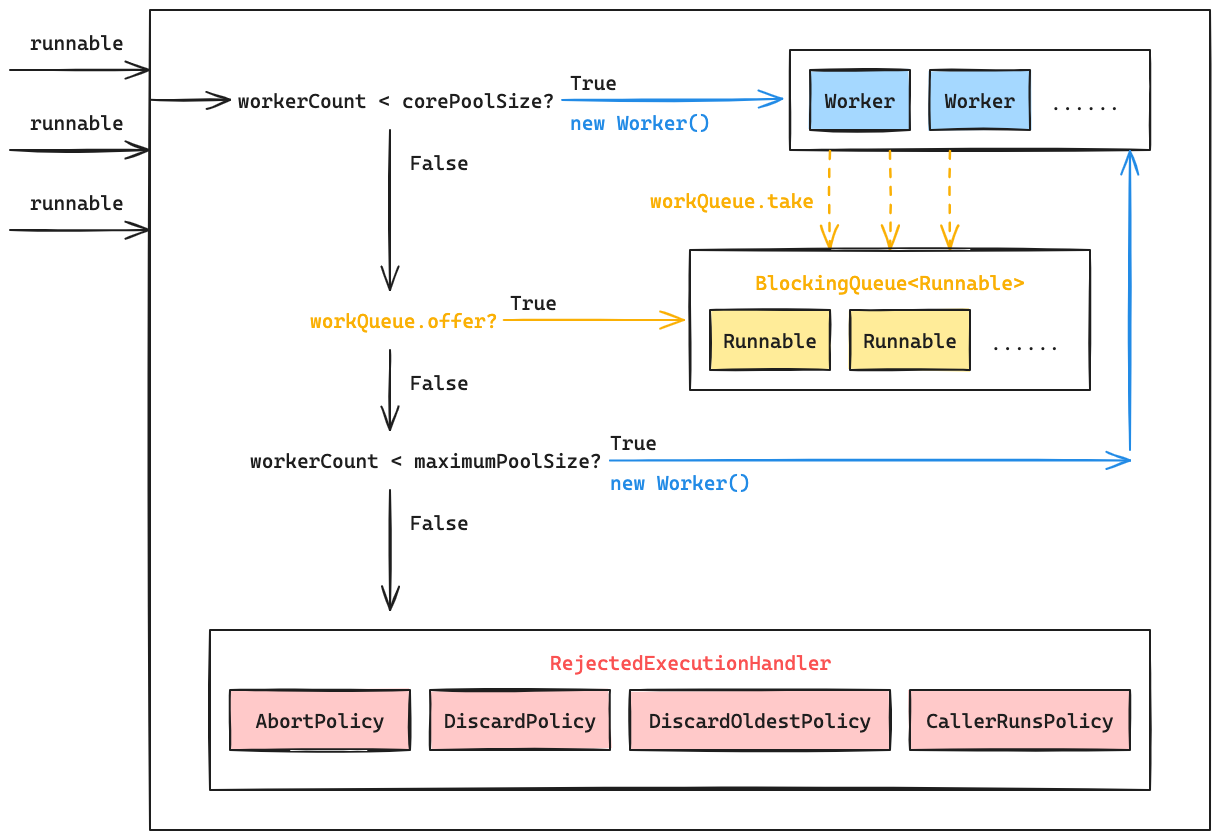
ThreadPoolExecutor 继承了 ExecutorService 接口,对外提供了四种提交任务的方法:execute(Runnable)、submit(Callable<T>)、submit(Runnable, T)、submit(Runnable)。然而,后三种方法均是先将任务封装成 RunnableFuture,然后再通过 execute(Runnable) 将任务提交至线程池中。因此从实现层面来看,ThreadPoolExecutor 所提供的提交任务的方法其实只有一种:execute(Runnable)。
ThreadPoolExecutor 提交任务的内部逻辑并不复杂,可以简单概括为以下四个步骤:
- 当 workerCount 小于 ThreadPoolExecutor 的核心线程数
corePoolSize时,ThreadPoolExecutor 会直接使用addWorker(command, true)方法来创建一个属于核心范围内的新的 Worker 线程。此时如果addWorker(command, true)方法执行成功,那么 ThreadPoolExecutor 会直接返回提交任务成功; - 当 workerCount 不小于
corePoolSize时,或者如果addWorker(command, true)方法执行失败,ThreadPoolExecutor 会使用 workQueue 的offer(command)方法来向队列中添加一个等待执行的任务; - 如果 workQueue 的
offer(command)方法执行失败(例如当队列已满时),ThreadPoolExecutor 会使用addWorker(command, false)方法来创建一个属于最大范围内的新的 Worker 线程; - 如果
addWorker(command, false)方法执行失败(例如当 workerCount 大于 ThreadPoolExecutor 的最大线程数maximumPoolSize时),ThreadPoolExecutor 会触发提交任务失败的拒绝策略。
ThreadPoolExecutor 的核心线程数 corePoolSize 和最大线程数 maximumPoolSize 以及 workQueue 决定了任务在提交时的行为,这些参数均可以通过 ThreadPoolExecutor 构造方法进行配置,并且前两者可以在已经创建 ThreadPoolExecutor 实例之后使用对应的 setter 方法进行修改。
ThreadPoolExecutor 源码中提交任务的方法 execute(Runnable) 的代码片段如下:
ThreadPoolExecutor 执行任务的最小单元是对 Thread 进行了一层封装的 ThreadPoolExecutor.Worker,更多关于 Worker 的分析请见 执行任务。ThreadPoolExecutor 通过使用 addWorker(Runnable, boolean) 方法来创建一个新的 Worker 线程,通过第二个布尔类型的参数来判断待创建 Worker 是属于核心范围内的线程还是属于最大范围内的线程(是应受到 corePoolSize 条件的限制,还是应受到 maximumPoolSize 条件的限制)。
ThreadPoolExecutor 先会在 addWorker(Runnable, boolean) 方法内部校验线程池的状态,例如 runState 当前是否为 RUNNING 枚举值、workerCount 是否符合 corePoolSize 条件的限制。在校验状态通过之后,ThreadPoolExecutor 则会创建一个 Worker 实例,并且会将这个实例添加到 HashSet<Worker> 类型的 workers 中的。值得注意的是,ThreadPoolExecutor 正是使用此处的 workers 来存放线程池中所有的 Worker 实例,并且 ThreadPoolExecutor 在访问 workers 时都会使用一个 ReentrantLock 类型的 mainLock 锁,以此来保证并发安全。
ThreadPoolExecutor 源码中创建 Worker 实例的方法 addWorker(Runnable, boolean) 的代码片段如下:
执行任务
ThreadPoolExecutor.Worker 继承了 AbstractQueuedSynchronizer,并且实现了 Runnable 接口,是 ThreadPoolExecutor 用于执行线程池中的任务的最小单元。
Worker 内部包含了三个变量:thread、firstTask、completedTasks。thread 是在创建 Worker 时使用 ThreadPoolExecutor 的线程工厂 threadFactory 来创建的 Thread 实例。firstTask 是在创建 Worker 时首次提交的任务。completedTasks 是 Worker 已经运行完成的任务数量。需要注意的是,在创建 Worker 时,传递给 threadFactory 的 newThread(Runnable) 方法的参数并不是 firstTask,而是实现了 Runnable 接口的 Worker 本身。因此当 thread 的 start() 方法被调用之后,thread 将会运行的其实是 Worker 内部的 run() 方法。
ThreadPoolExecutor 源码中定义 Worker 相关的代码片段如下:
Worker 内部的 run() 方法是开启 Worker 线程的入口,它会将 Worker 线程的主循环委托给 ThreadPoolExecutor 的 runWorker(Worker) 方法。在 runWorker(Worker) 方法中,Worker 线程会首先执行 Worker 内部的 firstTask 任务,在这之后 Worker 线程会重复执行使用 getTask() 方法从 workQueue 中获取的任务。Worker 会在每个任务执行之前调用 beforeExecute(Thread, Runnable) 方法,在任务执行之后调用 afterExecute(Runnable, Throwable) 方法,这种设计使得 ThreadPoolExecutor 对外提供了更多的扩展能力。
ThreadPoolExecutor 源码中运行 Worker 线程的方法 runWorker(Worker) 的代码片段如下:
回收线程
在 ThreadPoolExecutor 的 runWorker(Worker) 方法中,当 Worker 线程使用 getTask() 方法获取的任务为 NULL 时,Worker 线程便会退出主循环,继而该 Worker 线程便会结束和被回收。导致 getTask() 方法返回 NULL 的情况有以下两种:
- 在 ThreadPoolExecutor 处于关闭的情况下,
getTask()方法会直接返回 NULL; - 在 ThreadPoolExecutor 正常运行的情况下,如果
getTask()方法中的 workQueue 的poll(long, TimeUnit)方法返回 NULL,那么getTask()方法会先使用 CAS 操作将 workerCount 值减一之后再返回 NULL;
如果 ThreadPoolExecutor 中的 allowCoreThreadTimeOut 参数为 true,那么核心范围内的线程将也会参与回收机制。
ThreadPoolExecutor 源码中获取等待执行的任务的方法 getTask() 的代码片段如下:
拒绝任务
ThreadPoolExecutor 的拒绝策略由 RejectedExecutionHandler 接口定义,并且 ThreadPoolExecutor 在内部提供了四种适用于不同场景的拒绝策略:CallerRunsPolicy、AbortPolicy(默认)、DiscardPolicy、DiscardOldestPolicy。
CallerRunsPolicy 会将当前任务回退给调用线程,并且会在调用线程执中行任务,代码片段如下:
AbortPolicy 是 ThreadPoolExecutor 默认的拒绝策略,会直接抛出一个异常,代码片段如下:
DiscardPolicy 会抛弃当前任务,代码片段如下:
DiscardOldestPolicy 会抛弃 workQueue 中队首的任务,然后再尝试重新提交任务,代码片段如下: