Java CMS GC 优化案例两则
发表于 2020-11-25,预计阅读时间 3 分钟
前言
本篇文章简单记录自己在近期工作中遇到的两个 GC 相关的线上问题。
在谈及的两个案例中,应用均是使用 -XX:+UseConcMarkSweepGC 参数来指定使用了 CMS 收集器,因此本文对问题的分析和排查,也是基于该场景而言的。
知识储备
Heap 空间划分
JVM 中采用的分代收集算法的依据是一种假设:绝大多数的对象都是朝生夕灭的,熬过越多次数 GC 的对象越难以消亡。基于这种假设,在应用配置了 -XX:+UseConcMarkSweepGC 参数的场景下,JVM 会将 Heap 空间划分为 Young Generation(新生代)和 Old Generation(老年代),并且 Young Generation 空间会再被划分为 Eden、From Survivor 和 To Survivor,如下图所示:

在默认情况下,Young Generation 空间与 Old Generation 空间的大小比例为 1:2,即 Young Generation 空间会占用整个 Heap 空间占用 1/3,Old Generation 会占用整个 Heap 空间占用 2/3,该比例可以通过 -XX:NewRatio=${ratio} 参数来调节,同时也可以通过 -Xmn${size} 参数来直接指定 Young Generation 空间的大小。Young Generation 空间内的 Eden 空间与 From Survivor 空间、To Survivor 空间的大小比例为 8:1:1,该比例可以通过 -XX:SurvivorRatio=${ratio} 参数来调节。
分代 GC 过程
基于分代收集算法的假设,JVM 会对 Young Generation 空间和 Old Generation 空间采用不同的 GC 策略,其中对于 Young Generation 空间的 GC 被称为 Minor GC,对于 Old Generation 空间的 GC 被成为 Major GC,对于整个 Heap 空间的 GC 被称为 Full GC。
在 JVM 的设计中,新对象会优先被分配在 Young Generation 空间内的 Eden 空间。在经历一次 Minor GC 之后还存活的对象会通过「标记-复制」算法,和 From Survivor 空间内的对象一起,被 JVM 复制到 To Survivor 空间,同时 JVM 会直接清空 From Survivor 空间,并将当前使用的 To Survivor 空间作为下次 Minor GC 时的 From Survivor 空间。在经历多次 Minor GC 之后还存活的对象便会从 Young Generation 空间晋升至 Old Generation 空间,该最大晋升阈值可以通过 -XX:MaxTenuringThreshold=${threshold} 参数来调节。
Old Generation 空间比 Young Generation 空间更大,并且对象填充的速度也更慢,因此 Old Generation 空间发生 Major GC 的频率也会更低,但是在 Old Generation 空间所发生的 Major GC 会比在 Young Generation 空间所发生的 Minor GC 更加耗时。一次 Minor GC 耗时可能只需要几毫秒,然而一次 Major GC 耗时可能需要几十毫秒到几秒(取决于 Old Generation 的大小)。
在应用配置了 -XX:+UseConcMarkSweepGC 参数的场景下,JVM 会采用 ParNew 收集器来回收 Young Generation 空间内的对象,采用 CMS + Serial Old 收集器来回收 Old Generation 区域的对象。ParNew 收集器是一种多线程并行收集器,它在默认情况下开启的收集器线程数量与处理器的核心数量相同。在处理器核心非常多的环境中,可以通过参数 -XX:ParallelGCThreads=${threads} 参数来限制 ParNew 收集器开启的线程数量。
CMS 收集器是一种以获取最短停顿时间为目标的增量式(Incremental)的收集器,GC 过程分为四个阶段:初始标记、并发标记、重新标记、并发清除,其中的初始标记和重新标记阶段需要 Stop The World(即停顿工作线程),并发标记和并发清除阶段则可以和工作线程一起运行。
在 CMS 收集器运行期间,可能会由于无法处理「浮动垃圾(Floating Garbage)」而产生的「并发失败(Concurrent Mode Failure)」问题和基于「标记-清除」算法实现而带来的内存空间碎片化问题,导致 JVM 无法继续在 Old Generation 上分配新对象,从而导致 JVM 会采用 Serial Old 收集器来作为 CMS 收集器的备用选项,对整个 Heap 空间执行一次完全 Stop The World 的耗时更久的 Full GC。
案例一:频繁 Major GC
问题现象
在钉钉告警群内,间歇性地收到为某租户定制的应用接口超时告警,并且能在链路后台中统计到该时间段内的大量接口调用超时记录。
排查过程
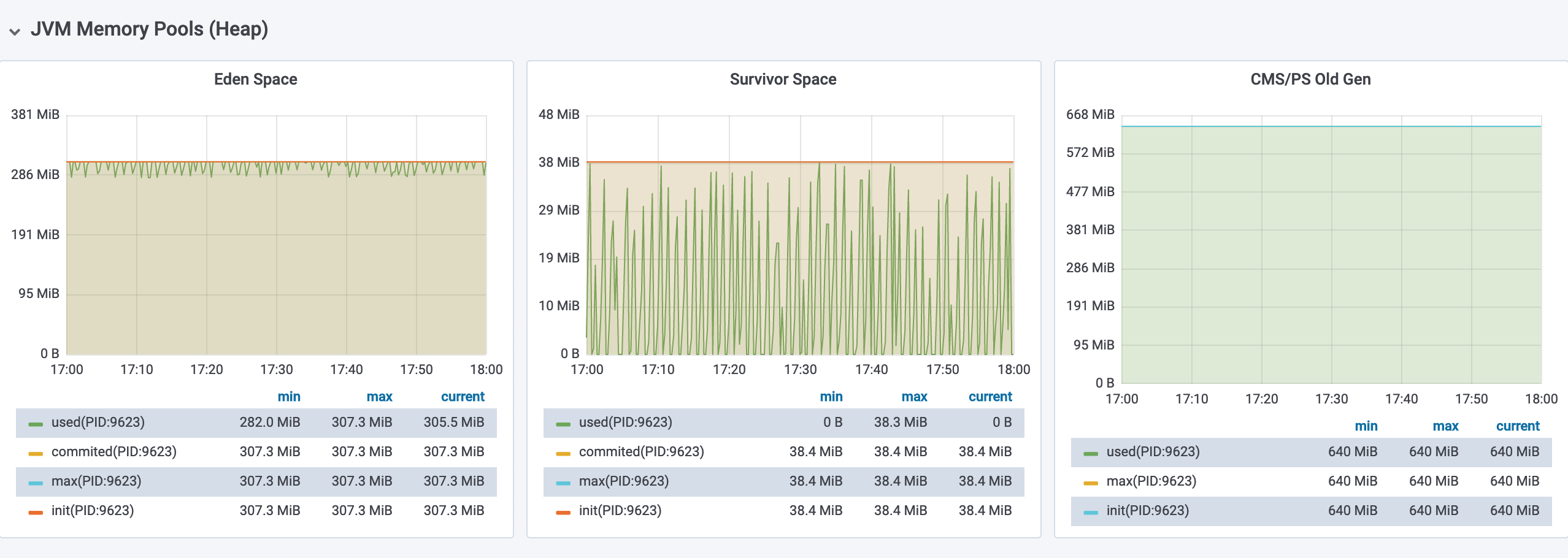
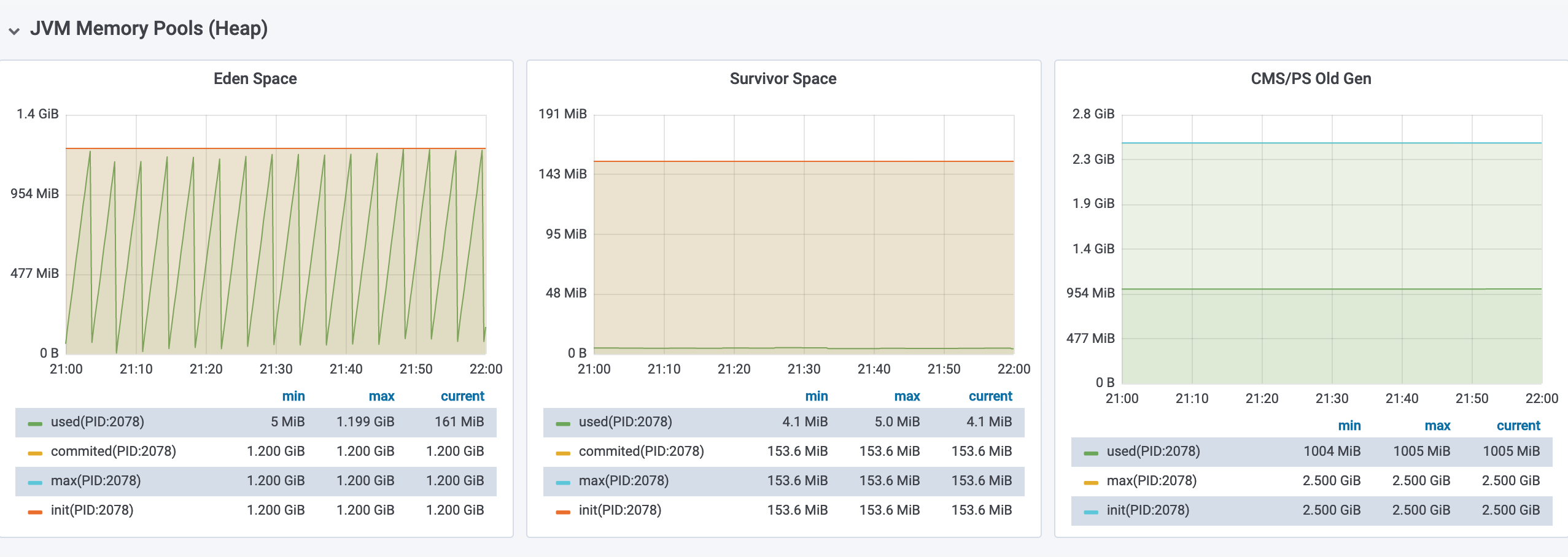
在监控大盘中,我们看到应用在出现问题的时间段内,CPU 和磁盘的使用率指标都有明显升高,更重要的,我们看到应用的 Heap 空间已经被占满,并且 Survivor 区域的使用率存在着大量峰刺形的波动。
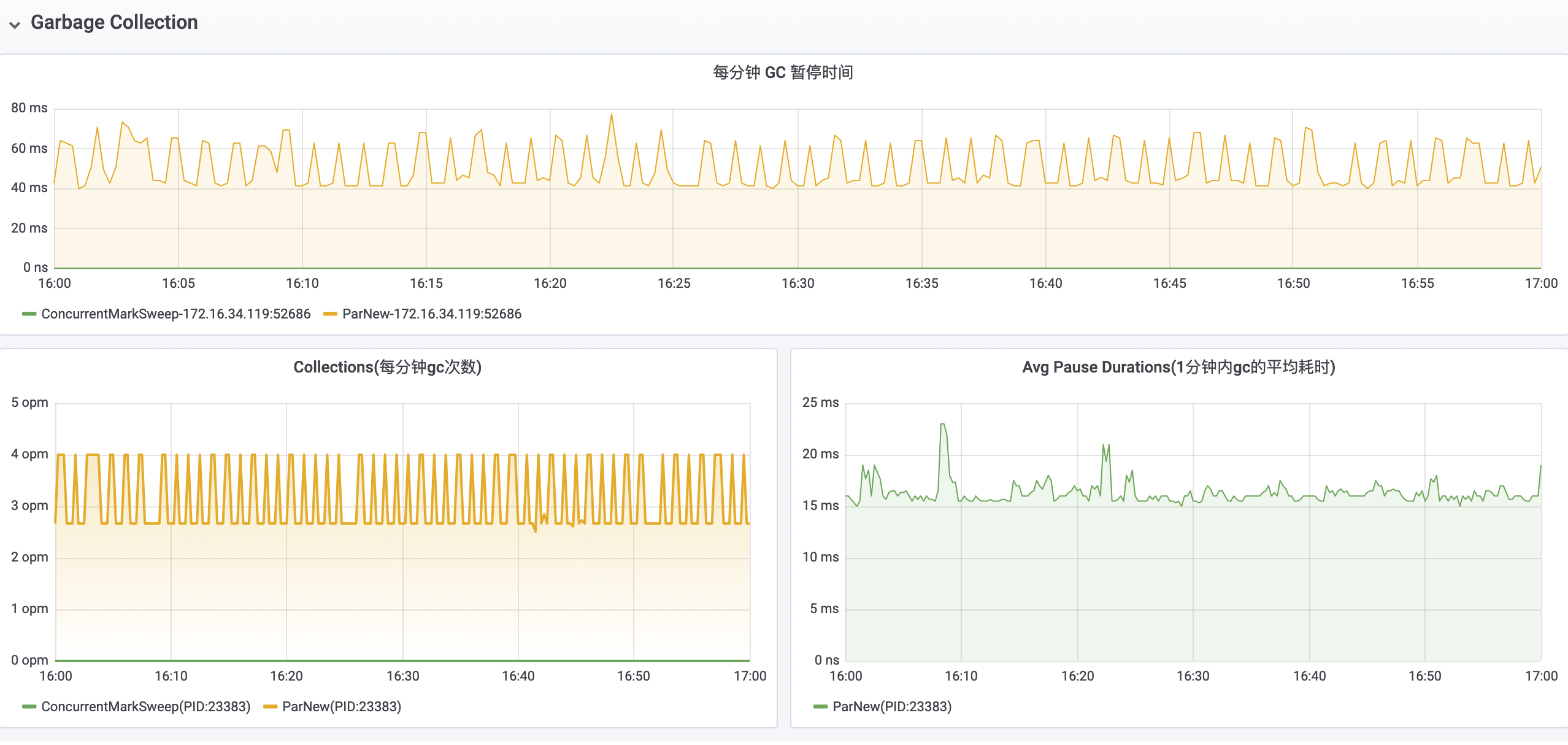
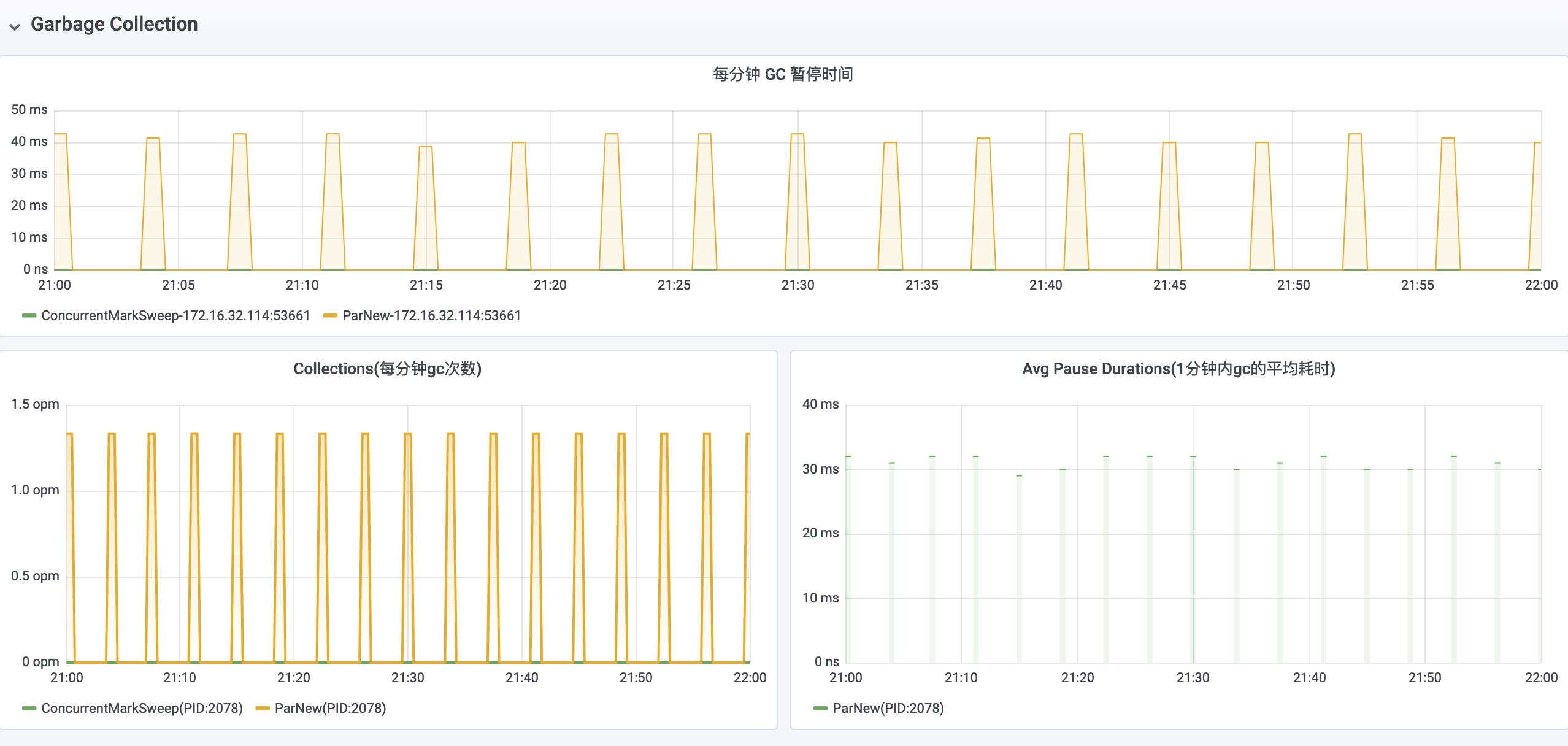
在 GC 方面,应用平均每分钟发生着 15 次 Major GC 和 5 次 Minor GC,并且每分钟的 GC 停顿时间甚至已经达到离谱的 20s。
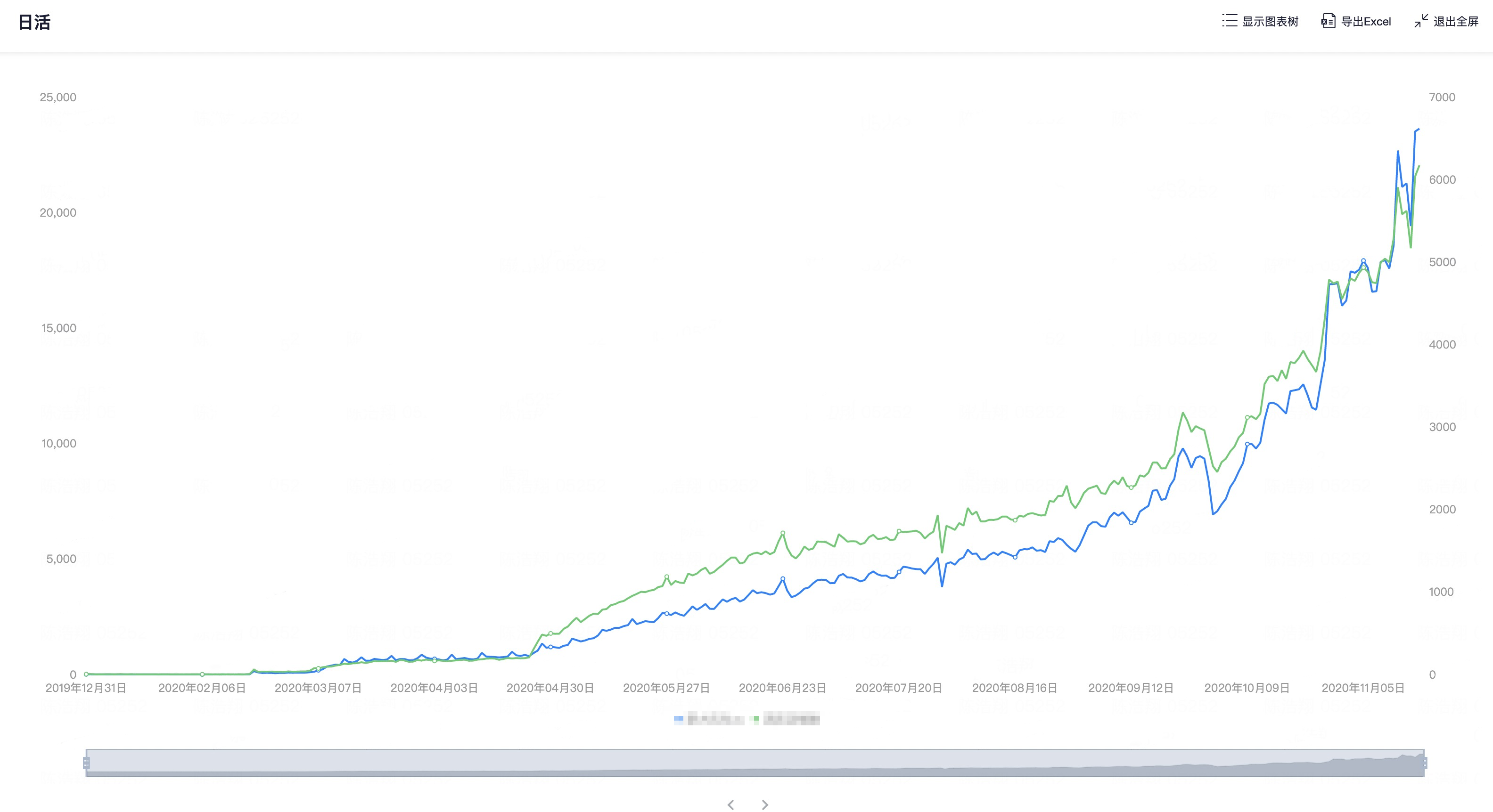
为了确定应用新增负载的来源,我们主动联系了业务方,得知他们最近迁移了一大波老用户数据,因此导致了应用近期承受的流量激增,最终超出了当前资源配置的可承受能力范围。
业务方反馈的近期用户日活数据变化如下:
问题解决
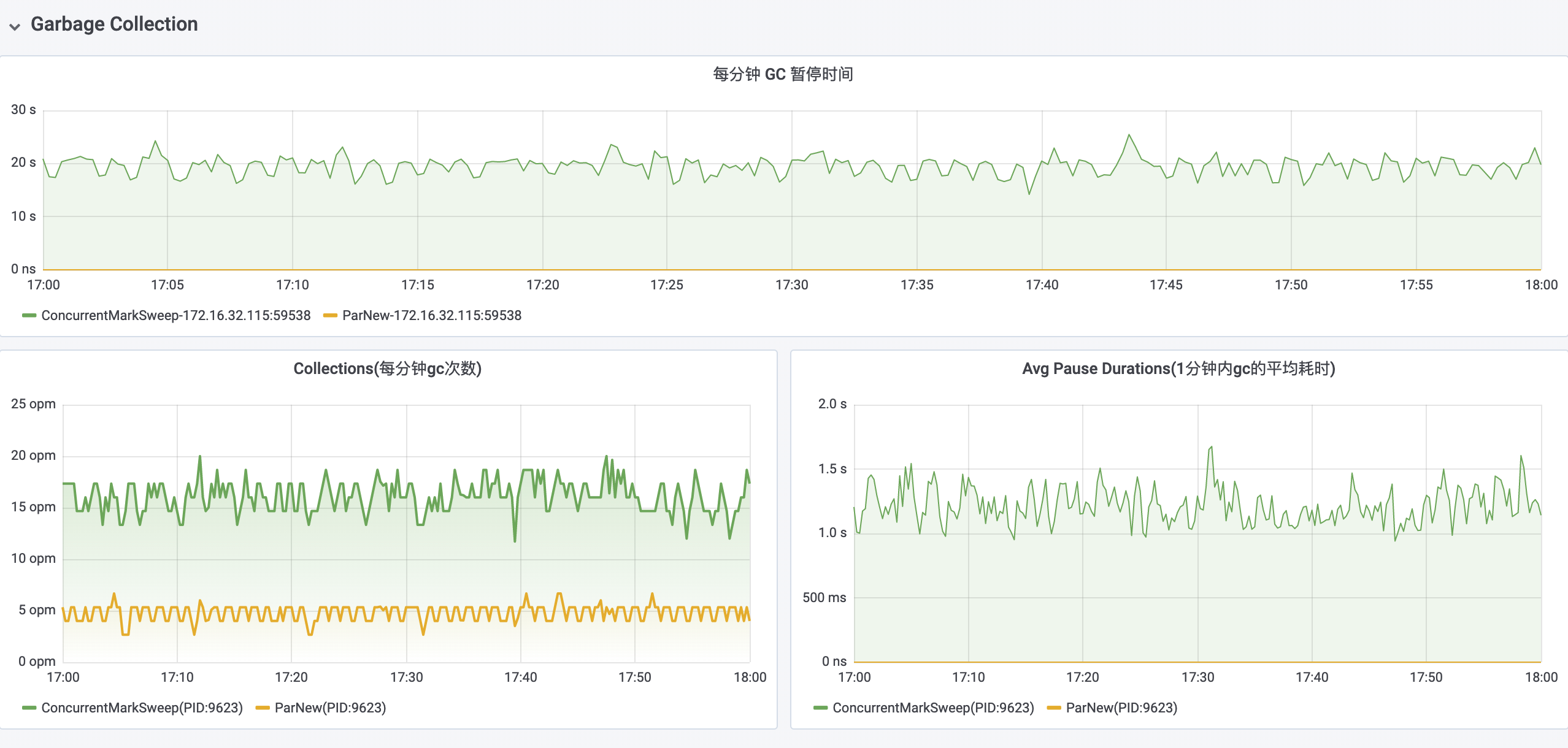
在明确问题根因为流量增加而导致应用不堪重负之后,我们紧急配合运维对该应用进行了升配:将 Heap 空间的大小从 1G 扩容至了 4G。在扩容之后,应用 GC 情况已经回归正常(Major GC 从 15opm 降低到了 0opm,Minor GC 从 5opm 降低到了 1opm,每分钟 GC 停顿时间从 20s 降低到了 40ms),接口超时问题也顺利得到解决。
后续复盘
在问题解决之后的复盘期间,我们还额外详细分析了应用在问题期间的具体 GC 情况。
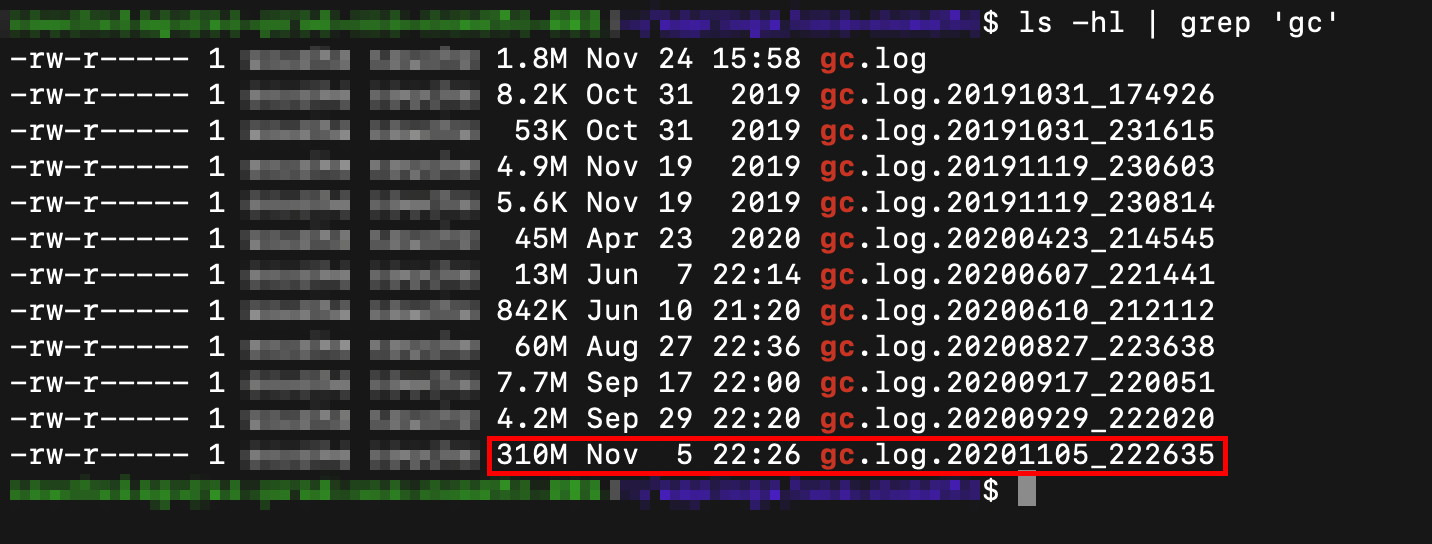
在登录服务器之后,看到最近一段时间内产生的 gc.log 文件非常之大,足足有 310MB。对 17:00 - 18:00 时间段内的 GC 情况进行统计,发现在这一个小时之内,应用共发生了 289 次 Minor GC、764 次 Major GC 和 10 次 Full GC。

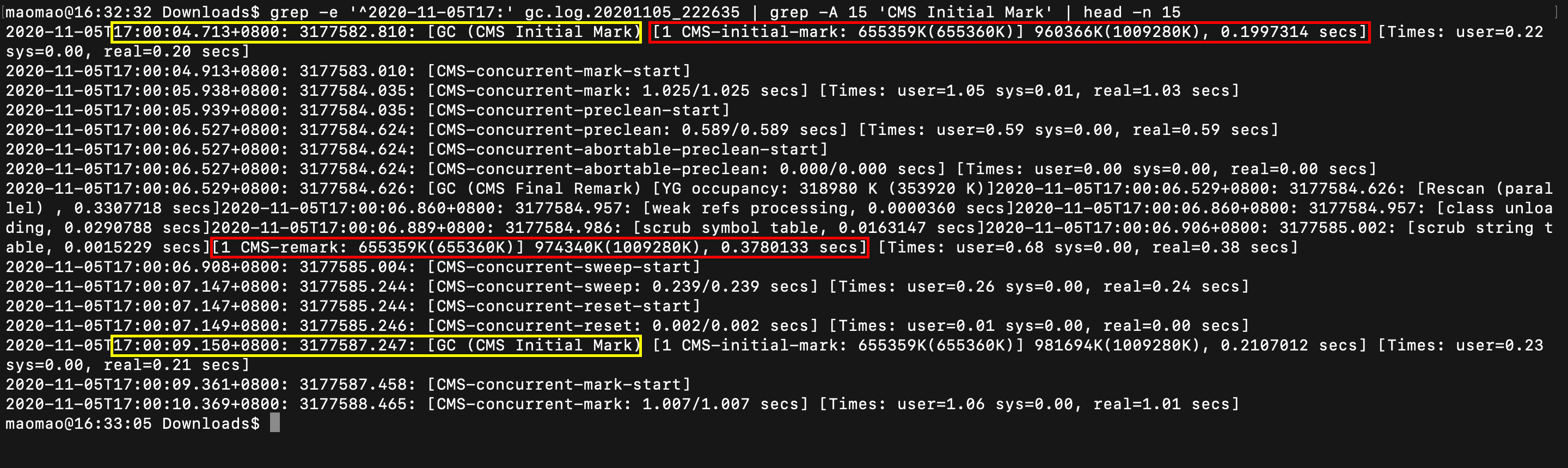
通过对 gc.log 中的 Minor GC 进行分析,发现应用在使用 ParNew 收集器执行一次 GC 之后,Young Generation 空间内的对象占用量几乎没变化。
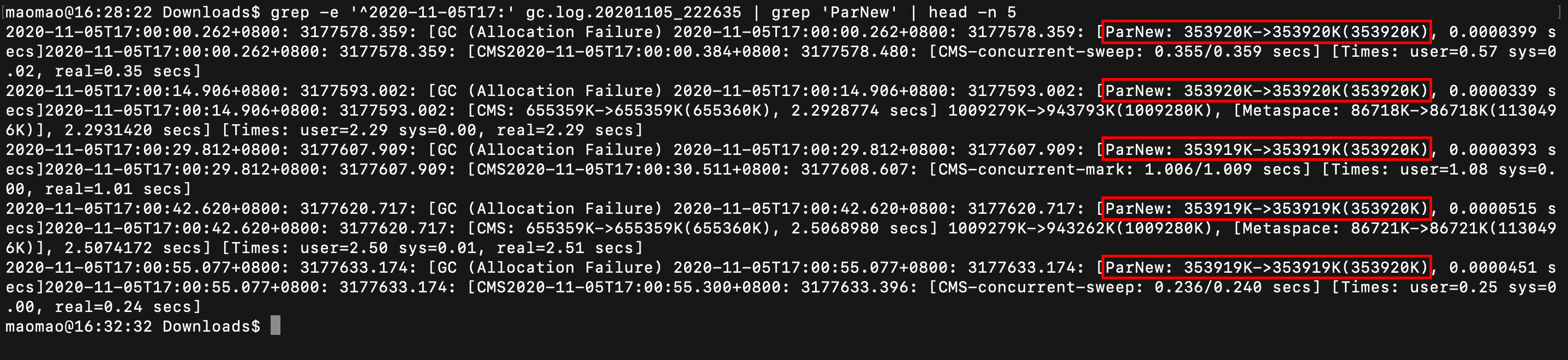
通过对 gc.log 中的 Major GC 进行分析,发现应用在使用 CMS 收集器执行一次 GC 时候,需要 Stop The World 的初始标记和重新标记阶段的耗时已经达到 500ms,并且连续发生两次 Major GC 的间隔时间不到 5s。
案例二:优化 Minor GC
业务背景
对于一个底层应用的接口,我们期望它的调用耗时尽可能短,在高峰时间段内对该接口的调用耗时进行统计之后发现,99.9% 的调用耗时在 8ms 左右,但部分偏高的调用耗时均大于 20ms,两者之间存在一个较大的断层,因此怀疑可能是由于应用 GC 停顿导致。

问题分析
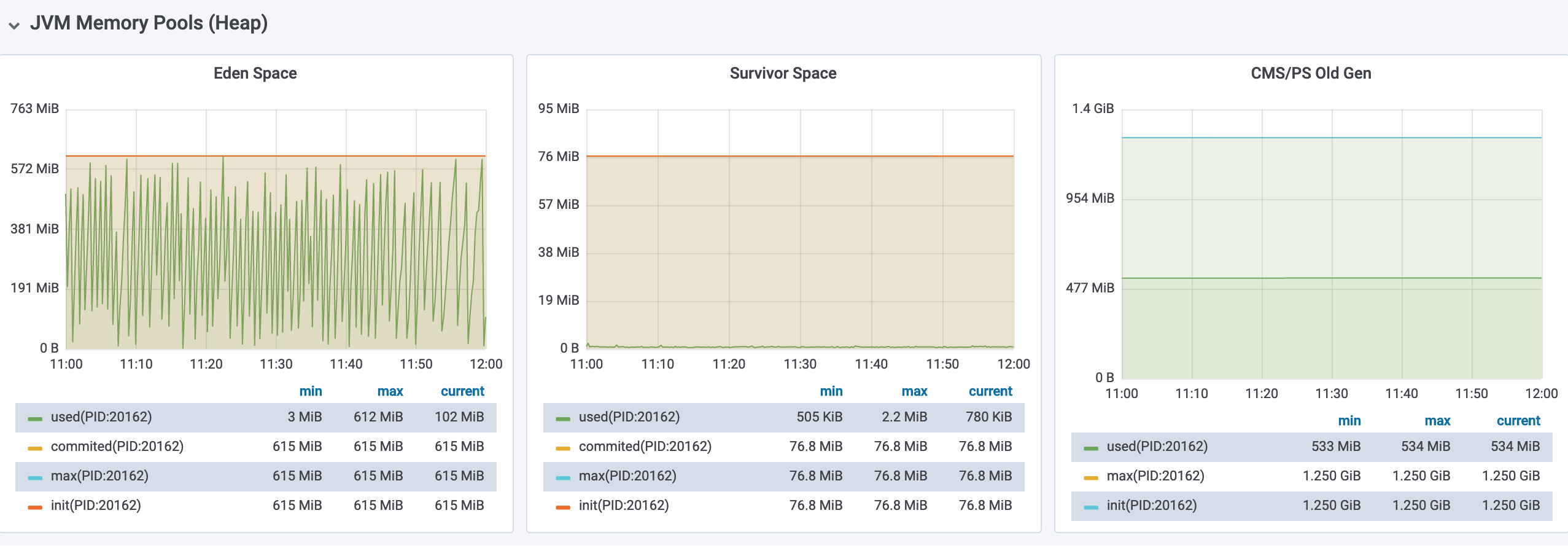
首先在监控后台中看到该应用被分配了 615MB + 76.8MB * 2 + 1.25GB * 1024 = 2GB 的 JVM Heap 空间大小,并且在应用运行期间主要发生 Minor GC,该应用在 11:00 - 12:00 时间段内平均每分钟内发生 5 次 Minor GC,每分钟内 GC 停顿的时间大约为 100ms。
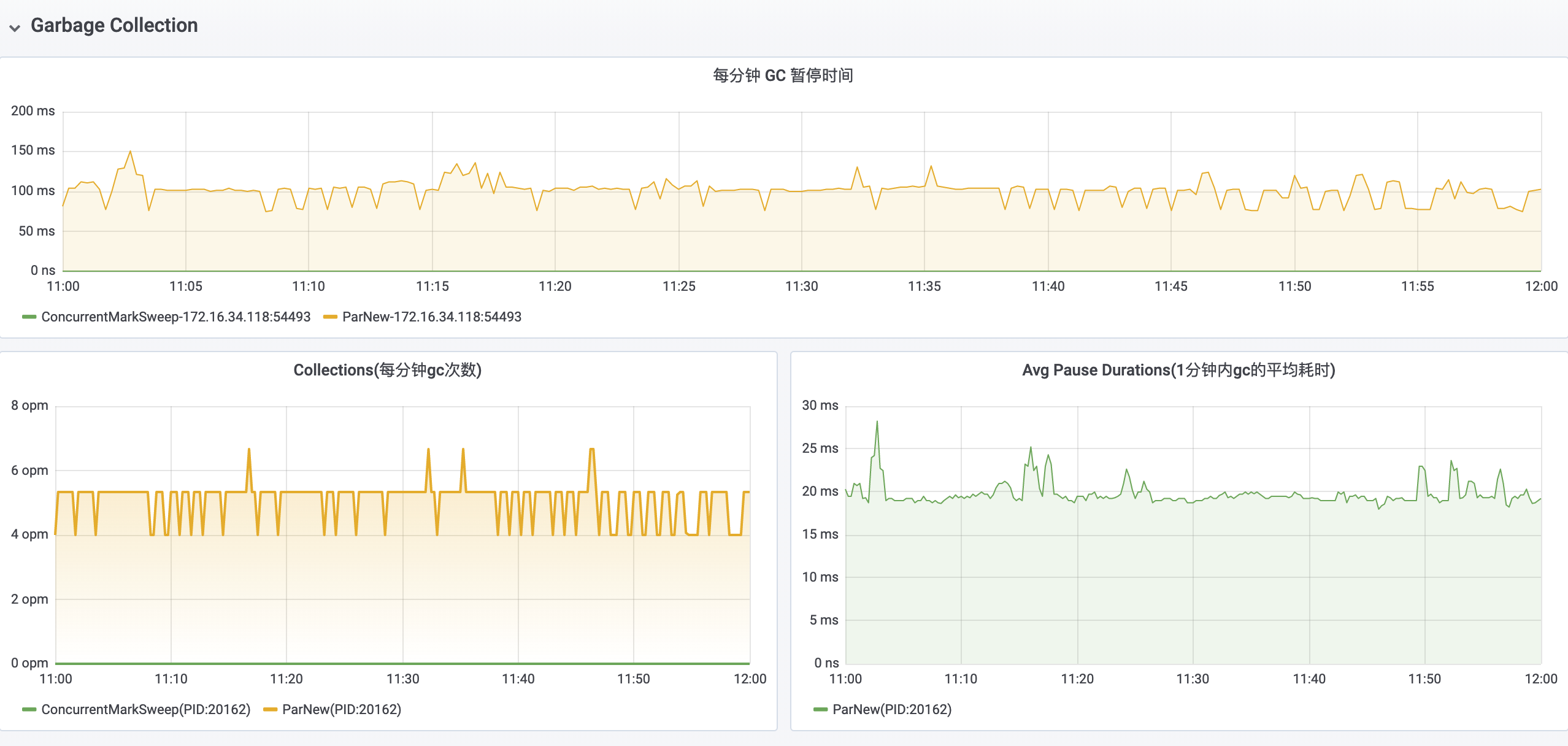
然后尝试通过 gc.log 来查看该应用的具体 GC 情况,发现该应用自启动 20 多天以来没有发生过一次 Major GC,但是平均每 10s 左右会发生一次 Minor GC,每次 Minor GC 的耗时大约为 15ms。


优化方案
在对该应用的 GC 情况进行分析之后,考虑到该应用的 Old Generation 空间内的对象占用量十分稳定,并且几乎不会发生 Major GC,于是便配合运维对该应用的 Young Generation 空间与 Old Generation 空间的大小比例进行调整,在保持整个 Heap 空间大小不变的情况下,下通过 -Xmn${size} 参数增加了 Young Generation 空间的大小。
在对该应用进行 GC 参数优化之后,Young Generation 的执行频率从 5opm 降低到了 3.5opm,每分钟 GC 停顿时间也从 100ms 降低到了 50ms。